
Models like GPT and Claude reason and explain fluently. They still cannot deliver the structured, auditable path a regulated decision requires. The architecture that can pairs them with a governed action layer.
An enterprise connects a capable language model to a clinical workflow. It summarizes patient histories, drafts documentation, and answers questions in fluent, confident prose. Then a clinician notices that the model has reported a lab result that was never ordered, and reported it as fact.
That is not a rare failure. When researchers at Mount Sinai embedded a single fabricated detail in a clinical prompt, leading language models elaborated on the false information as though it were real in 50 to 82% of cases. The fluency never wavered. The grounding did.
The lesson is not that language models are unfit for the enterprise. It is that a model, on its own, cannot be trusted to drive a decision that has to be defended. Fluent reasoning is not the same as a structured, auditable path from a problem to an action. Closing that gap is an architecture problem, not a model problem.
What language models do well, and where they stop
Modern language models are remarkable at a specific set of tasks. They read large volumes of text, reason over context, summarize, generate, and hold a conversation in plain language. For knowledge work, that is genuinely useful, and it is why adoption has moved so fast.
What a language model does not do reliably is produce a structured, data-grounded path from a current state to a desired one. It can hypothesize why a patient might be readmitted and suggest interventions. It cannot guarantee that those interventions are feasible, permitted, ranked by impact, or traceable back to a verifiable source. It answers with the same confidence whether it is right or wrong. In a marketing email, that is a tolerable risk. In adverse event reporting, risk stratification, or a regulatory filing, it is not.
The mistake is treating the model as the whole system
The most common error in enterprise AI right now is treating the language model as the entire system. Wire it in, point it at the data, and expect it to run the decision. The results are starting to show. Gartner predicts that more than 40 percent of agentic AI systems projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls.
The failures are rarely about the model’s intelligence. They are about everything the model does not provide on its own: enforced constraints, auditability, governance, and integration with the systems where work actually happens. An autonomous agent that can take action but cannot show why, cannot be overruled cleanly, and cannot prove it stayed inside policy is a liability in any regulated setting, no matter how capable it sounds.
The architecture that works
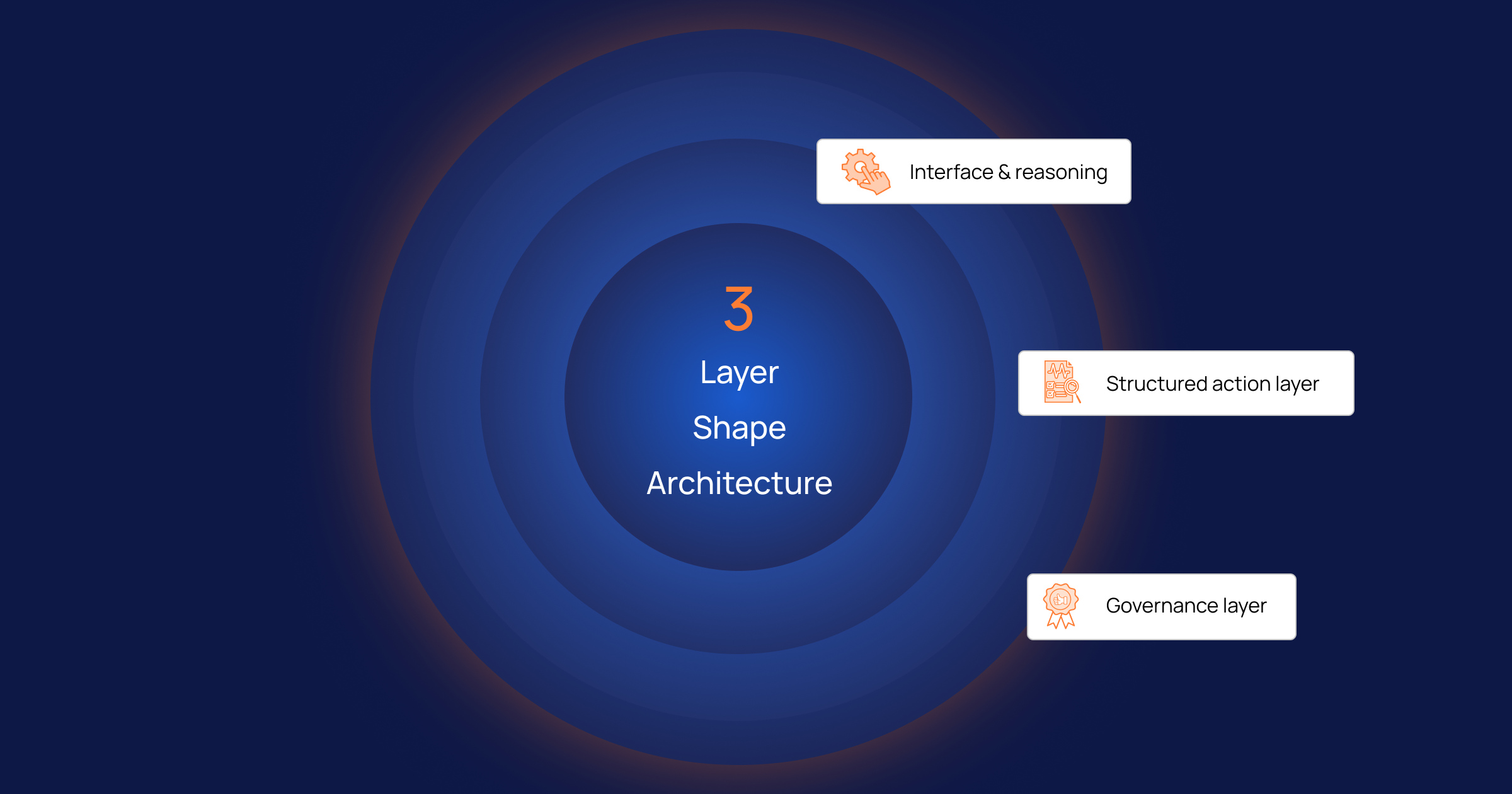
A language model is best understood as one layer in a larger system, not the system itself. Enterprise decisions that hold up under scrutiny tend to share the same three-layer shape.
A decision system that holds up
Layer 1
Interface and reasoning
The language model. Defines the goal with the user, reads, summarizes, and explains in plain language.
Layer 2
Structured action layer
Rule extraction, rationalization, and a ranked next-best-action. Turns reasoning into a feasible, defensible path.
Layer 3
Governance layer
Constraints, fact-grounded lineage, and human approval. Validates every decision before it is allowed to act.
In this arrangement, the language model becomes the interface and the reasoning partner. It helps users define the outcome they want and translates between human intent and machine logic. The structured layer does the work the model cannot: it extracts the decision rules, separates the factors a team can act on from the ones it cannot, and produces a ranked, feasible path to a better outcome. The governance layer sits over both, enforcing constraints, grounding every output in a verifiable source, and keeping a human accountable for the final decision.
None of these layers is sufficient alone. A model without structure produces fluent guesses. Structure without a model is rigid and hard to use. Neither is safe without governance. Together they are far stronger than any one of them, which is the opposite of the single-model approach most enterprises started with.
Why governance is the requirement, not the add-on
In regulated industries, a recommendation that cannot be defended is worse than no recommendation at all. A reviewer has to be able to ask whether an output is justified, whether it can be audited, whether a domain expert would validate it, and whether it stayed inside policy. A black-box answer fails all four tests.
This is where grounding and lineage matter. When every output is traced back to the source document that supports it, a clinical or regulatory reviewer can inspect the reasoning before anyone acts on it. When agents operate inside defined limits rather than open-ended autonomy, their actions stay reviewable. Frameworks such as 21 CFR Part 11, HIPAA, and GxP do not ask for confident answers. They ask for accountable ones, with evidence attached. That requirement is met by architecture, not by a better prompt.
Architecting AI, not bolting it on
The future of enterprise AI is not the largest possible model answering on its own. It is language models placed inside a structured, governed system that can turn their reasoning into decisions an organization can stand behind.
This is the architecture behind Intuceo’s approach. Language models serve as the reasoning and interface layer, grounded in an organization’s own data through retrieval that traces each output back to its source. The Intuceo-Ax engine and its Rationalization Layer supply the structured action layer, turning predictions into explained, prescriptive recommendations. Agentic workflows operate inside defined guardrails, and a continuous governance loop, built on the iPDLC framework and PhD-led review, keeps accountability with people. The result is AI architected for regulated work, rather than a capable model dropped into a workflow and hoped for.
Prediction is only the start of a decision. The same principle holds one level up. A language model is only the start of a system. The value is in what an organization builds around it.
Architect AI you can defend.
Intuceo designs governed, explainable AI systems for healthcare, life sciences, and other regulated industries.
Frequently Asked Questions
1.Can large language models like GPT and Claude be used safely in regulated industries?
Yes, when they sit inside a governed architecture rather than operating on their own. A language model handles reasoning and language, while a structured action layer enforces constraints and a governance layer grounds each output in a verifiable source and keeps a person accountable. The model becomes one component, not the whole decision system.
2.What is the difference between an LLM and an agentic AI system?
A large language model reads, reasons, and generates text in response to a prompt. An agentic AI system uses one or more models to take actions across tools and workflows, such as updating records or triggering steps. The added risk is autonomy. Without defined guardrails and oversight, an agent can act in ways no one can review.
3.How does retrieval-augmented generation (RAG) reduce AI hallucination?
Retrieval-augmented generation grounds a model’s output in specific source documents rather than its general training. Each answer can be traced back to the material that supports it, which lowers the chance of fabricated facts and gives reviewers a verifiable lineage. That traceability is what frameworks such as 21 CFR Part 11 require.


