Life sciences have a data problem disguised as a data advantage. Genomic sequencing, clinical trials, laboratory instruments, safety databases, and decades of research literature now generate information faster than scientific teams can study it. Researchers projecting data growth to 2025 placed genomics on par with or ahead of astronomy, YouTube, and Twitter among the most demanding sources of big data in the world.[1] Volume is rarely the constraint. Converting it into decisions is.
That gap is why so many research and data leaders are evaluating an advanced analytics tool for life science data. The category promises to automate the slow, manual work of preparing and exploring data so scientists can spend their time on interpretation. The label, though, gets stretched across everything from generic dashboards to specialized research systems, and the wrong choice can stall a program for months. This guide covers what advanced analytics in life sciences actually does, why generic tools struggle with research data, and the criteria that separate a real fit from a demo that looks good and fails in production.
What advanced analytics does for life science data
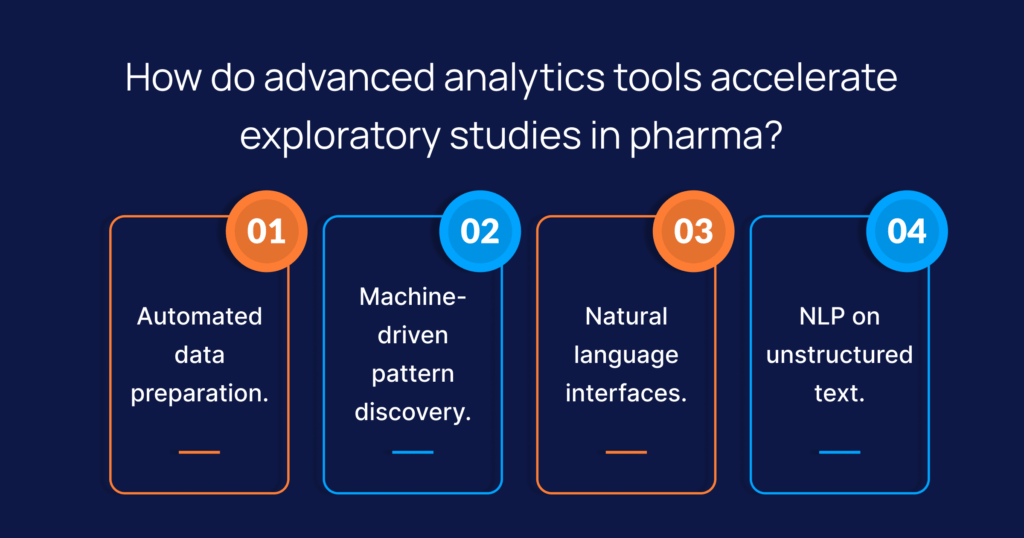
Advanced analytics applies machine learning and natural language processing to the analytics workflow itself. Rather than an analyst manually cleaning data, building a model, and hand-writing every query, the system profiles and prepares the data, surfaces patterns and anomalies, and lets people ask questions in plain language.
For research data, AI-powered analytics for life science data has to do more than chart tidy numbers. It has to make sense of structured lab results sitting beside free-text clinical notes, genomic files, imaging metadata, and PDF regulatory filings. The tools that hold up combine four things: automated data preparation, machine learning analytics for pattern and outlier detection, natural language processing that pulls meaning from text, and conversational querying that returns answers tied back to their source. Spending reflects the pressure. The life science analytics market is projected to reach $16.33 billion by 2030, with research and development being the fastest-growing segment.[2]
Why generic analytics tools struggle with research data
Most analytics tools were built for clean, columnar business data. Life science data is neither clean nor columnar.
Start with a format. Structured, coded data accounts for only 50 to 70% of the information relevant to a clinical trial, and nearly 80% of healthcare data is unstructured, held in clinical notes, imaging reports, and physician narratives.[3] A tool that reads only clean, structured tables ignores most of the available evidence.
Then scale and fragmentation. A single program can span genomic files, electronic health records, LIMS and PLM systems, trial databases, and patent libraries, each in its own format and silo. Joining them by hand is where weeks disappear.
Finally, regulation. In a GxP environment, an insight is only useful if it can be defended. A tool that cannot show how data moved from source to result, or explain why a model reached a conclusion, will not survive an audit. This is the failure point that generic advanced analytics in life sciences deployments hit most often.
Criteria for choosing an advanced analytics tool for life sciences data

It reads unstructured data, not just tables
The first test is whether the tool can work with the share of data that does not fit a spreadsheet. Look for native handling of clinical text, documents, and imaging metadata, and for natural language processing life science insights that extract findings from research papers and trial records rather than leaving them unread.
It automates data preparation
Data preparation is the slowest part of most analyses. Strong tools deliver data preparation automation for life sciences by profiling sources, flagging quality issues, and standardizing formats before modeling begins. The right level of automation returns scientist hours to science instead of spreadsheet cleanup.
It is genuinely self-service for non-data scientists
Many vendors describe a self-service AI platform for life science teams; far fewer deliver one. The practical question is whether a clinical, regulatory, or commercial lead can reach an answer without writing code or waiting in a queue. Conversational AI for life science data analysis helps here, letting users interrogate data in plain language and receive statistically grounded answers, not just generated text.
It explains itself and proves compliance
For regulated work, explainability is not optional. Every insight needs a verifiable path to its source, and every model decision needs an auditable rationale aligned with 21 CFR Part 11, GxP, and HIPAA. A cloud-based advanced analytics solution that cannot generate that evidence creates compliance risk, no matter how fast it runs. This is also how life science companies ensure data compliance in analytics: by choosing tools where traceability is built in, not bolted on later.
It fits existing pipelines
The tool has to work with what you already run. Before committing, confirm which ML tools integrate with existing life science data pipelines, including your data lake, EHR connections, and current BI surfaces such as Tableau, Qlik, or Spotfire. A tool that forces a full rebuild rarely justifies the disruption.
It supports predictive and prescriptive work
Descriptive reporting tells you what happened. Predictive analytics for the life science industry tells you what is likely next, and prescriptive modeling recommends the next action. Tools that embed forecasting, anomaly detection, and next-best-action into the same workflow move teams from reactive reporting to earlier intervention. Applied to machine learning analytics on healthcare data, that shift is the difference between explaining a missed signal and catching it in time.
How Intuceo approaches life sciences analytics
Intuceo’s PhD-led engineers bring Intuceo-Ax as an accelerator built on previous projects’ expertise, so the capabilities above arrive proven and then get configured to the data, pipelines, and compliance demands of the program in front of them.
DataSharp automates data preparation across structured and unstructured sources. InsightExplorer supports what-if analysis, and HiddenInsights surfaces root causes and patterns that manual review misses. A natural-language layer lets non-technical leaders reach institutional insights in as few as three clicks, with every answer backed by traceable data lineage rather than an unexplained number.
For the unstructured side, Intuceo-Ix builds a unified knowledge layer across research silos, indexing millions of documents spanning LIMS, PLM, clinical trials, FDA filings, and patents so teams find what they need in minutes. Where most models return only a yes or no, Intuceo’s explainable AI frameworks also generate the rationale that GxP review demands.
The distinction that matters for buyers is that Intuceo delivers this as engineering work, not a license to administer on your own. The criteria above get applied to your data and your regulatory context; the engagement model is fixed-bid rather than open-ended, and the controls that regulated research depends on are part of the build.
Before you commit, test it on your most complex datasets.
Most advanced analytics decisions go wrong at the pilot stage, when a tool that demos well stumbles on real clinical text, messy source data, or a single audit question. Intuceo’s engineers can run a sample of your own data against the criteria in this guide and show you where each option holds and where it breaks, before you commit to one.
Frequently Asked Questions
1.How do I choose an advanced analytics tool for life sciences?
Start with your data, not the demo. Confirm the tool can read unstructured sources such as clinical notes and filings, automate data preparation, explain outputs for audit, and connect to existing pipelines. A tool that scores well on these but looks plain often beats a polished one that only handles clean tables.
2.Is there a self-service AI tool for non-data scientists in biotech?
Yes, though capability varies widely. The marker of a real self-service approach is whether a scientist or commercial lead can ask a question in plain language and act on a sourced answer without engineering support. Conversational querying and automated data preparation are what make that possible.
3.How do life science companies ensure data compliance in analytics?
By choosing tools that build traceability and explainability into the workflow. Every result should carry a verifiable lineage to its source, and every model decision should produce an auditable rationale aligned with 21 CFR Part 11, GxP, and HIPAA. Compliance added after the fact is far harder to defend.
4.Can natural language processing extract insights from medical literature?
Yes. Natural language processing converts research papers, trial protocols, and safety reports into structured data that can be analyzed alongside numeric results, surfacing connections that would otherwise stay buried in text.
5.How does Intuceo-Ax help with life science data analytics?
It automates preparation across structured and unstructured data, surfaces patterns and root causes, and answers plain-language questions with traceable lineage, all under compliance controls suited to regulated research.