Why Pharma Analytics Teams Struggle to Scale Augmented Analytics Experiments
For most pharmaceutical analytics leaders, the celebration after a successful pilot project is short-lived.
It is relatively easy for a talented data team to build a convincing proof of concept – a targeted model that flags an adverse event faster, or a sleek commercial dashboard that answers questions in plain language to impress a steering committee. The real friction begins exactly twelve months later, when that same pilot is expected to run reliably across different regional markets, therapeutic areas, and highly regulated business units.
This bottleneck isn’t just an internal frustration; it reflects a massive global disconnect between digital intent and operational reality. While the global augmented analytics market is on track to rocket from USD 16.60 billion in 2023 to nearly USD 97.87 billion by 2030,1 organizations are finding that buying the technology is the easy part. McKinsey’s recent global benchmarking data shows that while a staggering 88% of organizations have successfully deployed AI within at least one business function, only about a third have managed to scale those capabilities across the wider enterprise
In the strictly regulated domain of life sciences, that execution gap is wider still.
Augmented Analytics: The promise, and the plateau
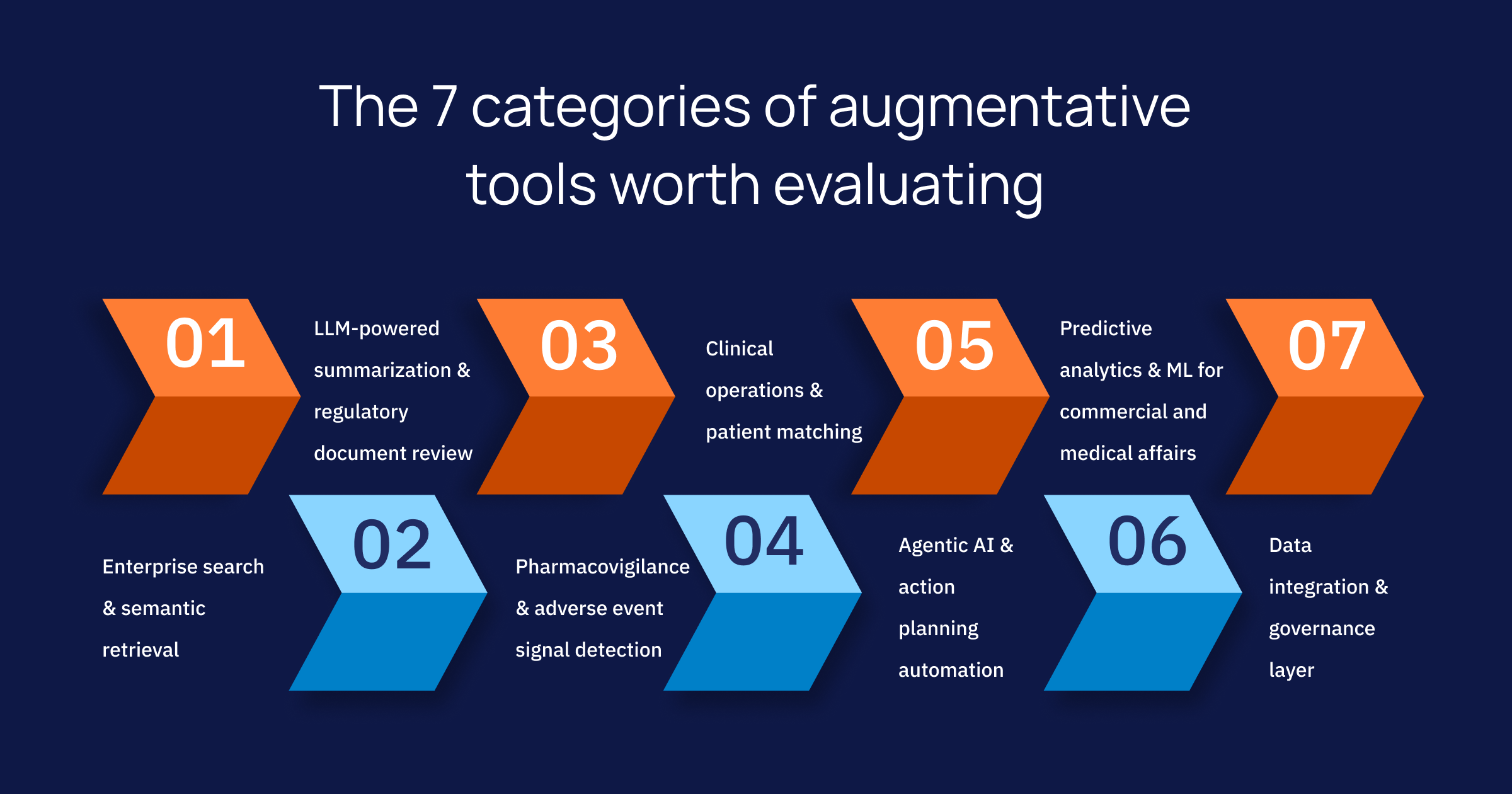
Augmented analytics uses machine learning and natural language processing to automate data preparation, surface patterns automatically, and let people question data in plain language. Today, this paradigm increasingly leverages Generative AI to provide fluid, conversational interfaces, turning what used to be complex database querying into a simple dialogue. For pharma, that transformation is highly practical: it means a clinical operations lead can interrogate trial site performance without writing a line of code, or a commercial team can test a complex market scenario without joining a three-week analyst queue.
The difficulty is the plateau that follows. Scaling analytics experiments is a completely different discipline from building them. A pilot succeeds in a controlled setting, with meticulously curated data and a highly motivated sponsor. Scale, however, demands messy production data, hundreds of simultaneous users, strict audit trails, and financial outcomes that a corporate finance team will defend. This is the underlying reason pharma analytics AI adoption so often stops at the demo.
Why pharma analytics experiments stall
Several forces compound at the same point in a program. Understanding them is the first step to explaining why AI pilots fail in pharma.

Data quality and fragmentation
Pharma data lives in silos: laboratory information systems, clinical trial databases, manufacturing execution records, safety systems, and commercial CRM systems, much of it unstructured. Industry data consistently shows that data scientists spend nearly half their working hours cleaning and preparing data rather than analyzing it. In pharma, this friction multiplies exponentially because regulated datasets cannot rely on approximations or ‘good enough’ data patches; a single missing data lineage link can invalidate a clinical report.
The validation and governance burden
A consumer analytics tool can ship and iterate. A regulated one cannot. Any insight that informs a clinical, safety, or manufacturing decision may need to be validated, traceable, and defensible to an auditor. Without regulated industry AI governance built in from the start, teams reach the pilot-to-production line only to find their experiment has no data lineage, no explainability, and no audit trail. Retrofitting those controls often costs more than the pilot did.
The business user adoption gap
Augmented analytics scales only when the people who make decisions actually use it. Yet many tools are designed for data teams, not for the clinical, regulatory, and commercial users who need the answers. When business user analytics adoption stays low, the experiment never leaves the analytics group and never changes how the business runs. Conversational analytics for pharma, where a user asks a question in everyday language and receives a defensible answer, is the bridge, but only when the interface fits the way that user already works.
Pilots built as demos, not workflows
When an enterprise solution is built to look good in a presentation rather than survive the realities of daily operations, failure is inevitable. This operational fragility explains why Gartner predicts that at least 30% of generative AI projects will be abandoned after proof of concept by the end of 2025. Because GenAI increasingly serves as the primary user interface for modern augmented analytics platforms, its high abandonment rate directly impacts the broader analytics ecosystem. Gartner points to poor data quality, inadequate risk controls, escalating costs, and unclear business value as the primary drivers of this collapse.
The common thread across these failures is not the underlying model itself; it is the infrastructure and conditions around it. Enterprise AI in life sciences fails in the exact same way. A pilot engineered solely to impress a steering committee in a boardroom is fundamentally different from a system engineered to scale securely across a global enterprise.
From experiment to enterprise impact
Moving from experimentation to enterprise-wide impact has less to do with a better model and more to do with a repeatable method. Teams that scale tend to do a few things differently. They start with a single high-value decision rather than a broad capability. They build governance, validation, and data lineage into the experiment instead of bolting them on afterward. They design for the business user from day one. And they treat the pilot as the first production increment, not a throwaway proof.
This is also where AI decision support in life sciences earns its place. Decision support that surfaces an insight quickly, shows the data behind it, and records how it was derived can be trusted, audited, and adopted. Decision support that produces an answer no one can explain will not survive a regulatory review, let alone reach scale.
How Intuceo helps pharma teams scale
Intuceo is a PhD-led AI, ML, and data analytics services firm that works inside regulated industries, including pharma and life sciences. The work is not about selling a tool. It is about delivering the method and the engineering that move an analytics experiment into dependable enterprise use.
Intuceo-Ax, the firm’s augmented analytics accelerator, is built to speed deployment rather than start every build from zero. It automates data preparation, supports what-if exploration, and lets non-technical leaders navigate deep KPIs in as few as three clicks, which speaks directly to the business user adoption gap. Because it draws on patterns proven in prior pharma engagements, teams skip much of the trial and error that stalls a first attempt.
Governance is engineered in, not added later. Intuceo applies a Regulated-by-Design approach: automated data profiling and anomaly detection at the source, immutable lineage for forensic traceability, and explainability frameworks with bias detection and model cards reviewed by a PhD-led Board of Science. These controls are pre-vetted against FDA 21 CFR Part 11, HIPAA, GxP, SOC 2 Type II, and FISMA requirements, giving regulated AI governance a concrete foundation.
The firm’s iPDLC framework gives experiments a defined route from concept to validated production, the step most pilots are missing. Across more than 100 life sciences engagements over 14-plus years, including work for organizations such as Janssen and Ferring, Intuceo has engineered solutions like a universal search capability that indexes over 5 million R&D documents, turning dormant knowledge into usable insight. Engagements run on fixed-bid and budgeted models, so clients pay for outcomes rather than activity.
Ready to Move from Pilot to Production?
Don’t let a promising experiment stop at the demo phase. Intuceo builds compliance, data lineage, and user adoption directly into your pipelines from day one.
- Regulated-by-Design: Pre-vetted compliance (FDA 21 CFR Part 11, GxP, HIPAA) built in, not bolted on.
- Proven iPDLC Framework: A predictable path from concept to an audited, enterprise-scale project.
- Outcome-Based Models: Fixed-bid structures so you pay for impact, not activity.
Frequently Asked Questions
1.Why do AI pilots fail in pharma analytics?
Most fail at integration, not at the model. Pilots run on curated data with a motivated sponsor, then meet fragmented production data, low business user adoption, and validation requirements they were never designed to satisfy. The experiment works in isolation but cannot connect to the workflows and controls that real scale demands.
2.How do life sciences teams move from experimentation to enterprise-wide AI impact?
By treating scale as a method rather than a milestone. That means starting with one high-value decision, building governance and data lineage into the experiment from the start, designing for the business user, and running the pilot as the first production increment. A defined lifecycle, such as Intuceo’s iPDLC, gives that progression a repeatable structure.
3.What governance is needed for AI in life sciences analytics?
At minimum: validated data quality, immutable lineage so any insight can be traced to its source, explainability so outputs can be defended, and bias detection and model documentation. These should map to standards such as FDA 21 CFR Part 11, HIPAA, GxP, and SOC 2 Type II, and should be present before a pilot is asked to inform a regulated decision.
4.How can pharma analytics teams reduce manual effort without losing compliance?
Automate the repeatable work, data profiling, preparation, and anomaly detection, while keeping validation and audit trails intact. Automation that records what it did and why preserves the defensibility a regulated environment requires, and frees analysts to spend time on interpretation rather than cleaning data.
5.How do you make augmented analytics useful for business users, not just data teams?
Meet users in their own workflow and language. Conversational analytics that let a clinical or commercial user ask a question and receive a clear, sourced answer removes the dependency on a specialist queue. Adoption follows when the interface is simple, the answer is trustworthy, and the path to that answer is short.